- Emergent AI
- Posts
- The not-quite bear case
The not-quite bear case
A healthy dose of skepticism
Ilan Man
July 02, 2025

As I’ve used and delivered AI-based apps and solutions, I find myself more and more enticed by the promise of AI. Lots of smart people are pushing it. Some even suggest we’re already at AGI, and the singularity will be boring, even gentle. I want boring right now1 .
But maybe we’re not slowly marching towards obsolescence. Maybe this is just a hype cycle like no other. I don’t necessarily think so, but it’s important to steel man the other side, or at least hold a skeptical view. So let’s dive into a few contrarian takes2 , to keep ourselves honest.
🤝 Alignment
AI is getting more accurate3 with every generation4. While hallucinations will always exist (these things are stochastic parrots after all, no matter how big they get), AI’s ability to distinguish between cat and dog (once a challenge) is now a solved problem. I mean, this is wild5 :
Will Smith can’t stop won’t stop
Gains in precision and accuracy notwithstanding, what about when AI does stuff that harms us? I don’t mean Skynet (yet), I mean stuff like:
Gaming the system to maximize the objective (sorting resumes based on past success biases against certain classes of people)
Optimizing social media watch time by promoting toxic (=addictive) videos, leading to depression among teenage girls (and making everyone in general feel shitty)
Vulnerabilities in the model (via jailbreak / deceptive prompts) lead the LLM to answer very harmful questions (like hurting oneself or others)
And the list goes on. These models are really good at optimizing for a target, but in the process, may be misaligned to what is good for humanity. This is the alignment problem.
If this sounds subjective or soft, then you’re right. In principle we could tell the model “Answer the question as accurately as possible without causing unintended harm to humans”. But even humans haven’t figured out how to solve that ourselves, and let’s be real, we never will6. This is what makes humanity and society messy, random, and evolving. That said, researchers are prioritizing the alignment problem, and it’s viewed as among the most important AI research topics today, and a key unlock for safe superintelligence.
🫰 No free lunch
Valuations for AI companies and AI people7 (lol) are exploding. Let’s be very clear here - this is not sustainable. This is worse than ZIRP in some ways, since at least during ZIRP more people benefited (specifically those who could take advantage) from the rising tide of low interest rates. In the AI story so far, the financial boom in the US is concentrated among a handful of VCs and Mag7s8, pumping up this entire ecosystem.
And just like the millennial lifestyle was operating on borrowed time (thanks Silicon Valley VC!), so is this AI boom. Not to take away from it’s potential economic impact or how it can improve society, it’s just not feasible for the curves to continue moving up and to the right at the same clip that they’ve been9 .
Remember, companies trade on future expectations - publicly trade stocks are valued as a multiple of their earnings (Price / Earnings ratio), while privately held companies are valued as a multiple of their revenue or EBITDA10 . So when those future expectations are inflated, their valuations will be as well. And for those companies that are privately held, their investors (which is not the public) are incentivized to keep pumping up their valuations (the higher the multiple, the more a dollar of their equity is worth).
Valuation multiples are very much an art. Investors look at the average of comparable companies (“comps”), and use that average as the valuation11. When you have juggernauts like OpenAI and xAI skewing valuations, that’s going to impact small and mid-size AI startups, inflating their valuations as well.
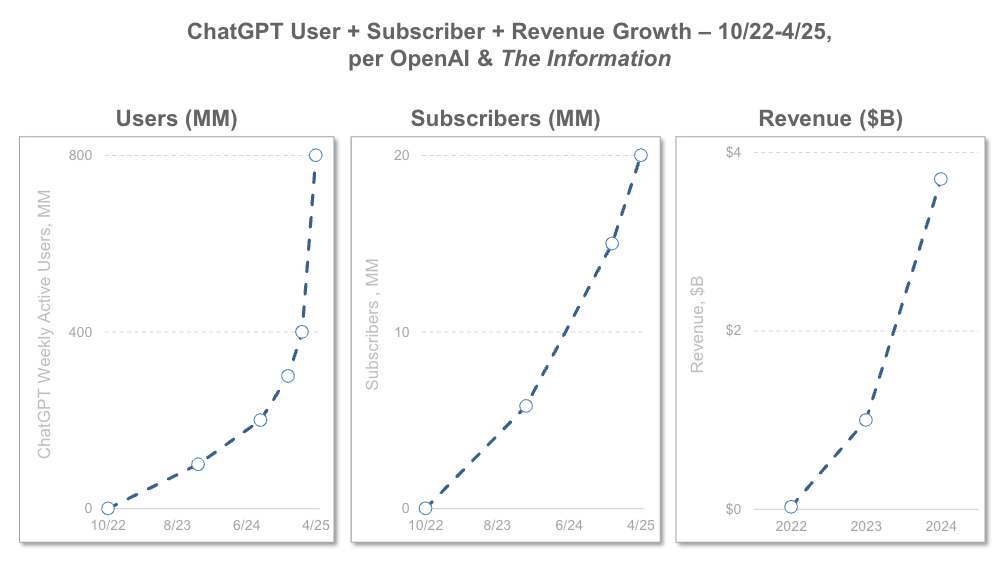
So what? When expectations are high, the hamster wheel spins faster. And eventually, investors will want their money back, since they’ll have been investing at higher and higher valuations (see above: pumping the value). That’s sort of their problem but also ours. When VCs demanded Uber and Grubhub start making a profit, we all had to pay up. That’s totally reasonable, since we were living in a fantasy world (buoyed by VC dollars and gig worker exploitation), so maybe it’s not a big deal that it’ll happen with all our AI tools. One of the differences however is that AI is becoming so deeply integrated into our lives, that it won’t be as easy to simply “use ChatGPT less often” in a few years. We’ll be hooked, especially younger generations. And yeah, that’s not OpenAI’s problem, but it’s still makes the AI utopia slightly less rosy.
⚡️ Theoretical limits
Recently Sam Altman spoke about how the cost of AI is reducing and “Eventually the cost of intelligence, the cost of AI, will converge to the cost of energy.” (because an electron is still an electron).
But to paraphrase Jevon’s paradox (every AI CEOs favorite paradox), the more available something is, the more people will use it. So yeah, things will get cheaper per query, but the number of queries are going up even faster12 . And the companies building these frontier models need ever bigger data centers (they are spending billions on these behemoths) to train bigger models.
It’s a tension - on the one hand, models and compute costs are going up in aggregate; on the other, the unit economics are getting more favorable (cheaper per query). There’s a physical limit to how cheap computation can get (electrons aren’t free), but there’s almost no limit to how much we’ll use AI - especially as “always on” and embedded use cases become the norm. Think of it like leaving your AC or lights on all day13, but now it’s AI running in the background of everything.
One of the (paradoxically) saving graces is that we’re running out of data to train larger models, which is a huge cost driver for AI companies (though less of a cost driver than inference).
⌛️ We’re running out of data14
I’ve mentioned before, but yeah, we’re running out of high quality, publicly available data. Some estimates put it between 2026 (unlikely) and 203215. Two key terms there:
High quality - the solve here is a technical workaround. Synthetic data, or other efficient algorithms to offset the shortage. Or we could live in a world up to our elbows in AI Slop due to AI inbreeding.
Publicly available - this is the big one that makes companies like Google, Meta and OpenAI so special. They have a lot of our personal data. And unless you think they are altruistic entities created for the public good (crazy idea I know) then they’re likely to leverage our personal data to supplement what’s available. And don’t forget the OG of data - they’re mining our books too!
This paints a dire picture for training newer and bigger (and therefore smarter) models down the road. Again, the curve can’t continue growing at its current pace. Something’s gotta give.
🧐 More skeptical than when I started
I find these exercises immensely helpful. It’s too easy to get caught up in the hype, and sometimes, I want parts of it to be true.
Sure, the list of potential benefits of AI are long. But there’s also an uneasy sense that the accelerating pace, the pile on, the silly money, and the scale of change is happening to us, not with us.
I’m going to continue using, learning about (and from) AI, and trying to help others adopt and leverage it for themselves. But in the meantime, I’ll continue to take a skeptical eye and keep my critical thinking handy, to be better prepared for when the robots take over.
1 Especially in these way too interesting times.
2 This is by no means an exhaustive list, just what I found interesting in the moment. There’s always a part 2 somewhere!
3 “Accuracy” is a catch all term for things like precision, consistency, realistic, robust, etc. choose your favorite objective
4 ish - some reasoning models, like o3, tend to hallucinate more!
5 And disturbing (especially the one on the left)
6 Ahh but therein lies the rub - we need AI to help us solve this very human challenge! Help us help ourselves!
7 My new favorite oxymoron
8 Pour one out for “FAANG”. Miss ya bud.
9 Yes, I read through the 340 slides of Mary Meeker’s deck, and they all go up (except for cost, which is going down). When something is too good to be true…
10 Depending on the community you’re adjusting for, I guess
11 To be fair there is a lot more that goes into this, but using comps is a standard practice starting point
12 A query is every time you ask the LLM something. When the LLM returns an answer, that’s called inference. Inference is the new primary driving factor in AI costs as more people use it.
13 As a child of Eastern Europeans, even imagining this hurts my soul
14 What a provocative statement! Basically, LLMs are trained on data from the internet - APIs, public datasets, web scraping. The problem is companies are restricting their API access (competition, copyright, etc), public datasets have been mined for years and are growing slowly, and web scraping, which is the rest of the internet, is becoming more and more polluted by AI generated content (SLOP!) or hidden behind paywalls (which companies may be reticent to release to LLMs). So yeah, somehow, we’re running out of data to train these models on.
Reply